AI code generation is starting to raise questions of long-term maintainability. However, not all generative models are in the same boat.
AI now makes it possible to generate code at an unprecedented rate, but maintainability is another matter entirely. The rise of vibe coding in business has further accelerated the problem: rather than producing maintainable code by default, AI agents generate functional code without natively integrating long-term constraints. Systematic installation of third-party dependencies, complete rewriting of existing stacks… the deviations are legion. A real wall for companies, which depends in particular on the underlying model. According to researchers at Sun Yat-sen University and Alibaba, not all LLMs generate the same quality of code over time. And the results of their research are surprising.
SWE-CI, to evaluate the maintainability of the code
To classify and evaluate the maintainability of the code generated by LLMs, researchers have developed a new benchmark 0: SWE-CI. The approach differs from classic SWE-bench code benchmarks, where the agent receives a bug and generates a one-shot patch. With SWE-CI, we no longer ask the AI to solve a one-off problem, but to maintain software over time. Concretely, we take a real open source software project (extracted from GitHub) and we give the AI its version from several months ago. Its mission: to evolve it to its current version, feature by feature, by chaining dozens of modification cycles. On average, the gap between the two versions represents 233 days of human development. The final dataset includes 100 tasks taken from 68 mature Python projects recognized by the developer community.
On the evaluation side, the model does not receive the list of modifications to make: it must discover them itself. At each cycle, it analyzes the gap between its version of the code and the target version, identifies priority problems, then corrects them. This cycle repeats up to 20 times per task. The researchers note the result with an in-house metric, EvoScore, which mainly values the quality of the code at the end of the process. A model that produces clean, well-structured code from the start will still have room to maneuver at the end, while a model that piles on patches will eventually collapse under its own weight.
Claude Opus 4.6 and GLM-5 at the top of the ranking
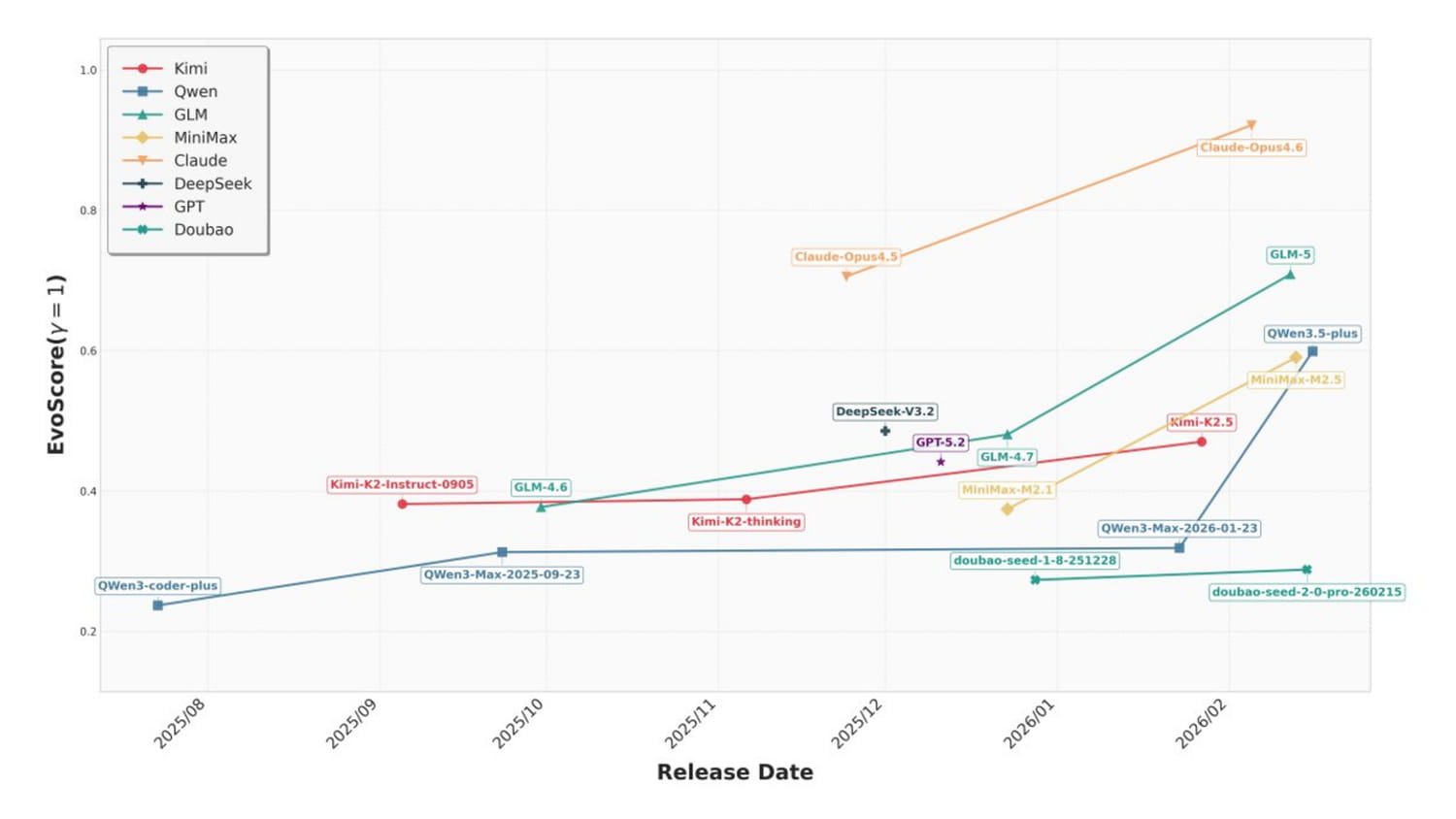
18 models from 8 different suppliers were screened. Claude Opus 4.6 largely dominates the ranking with an estimated score of around 0.85-0.90, far ahead of the rest of the peloton. Claude Opus 4.5 and GLM-5 follow in a range of 0.60-0.65, forming a second tier. Then come Qwen3.5-plus, MiniMax-M2.5 and Kimi-K2.5 around 0.45-0.50, then DeepSeek-V3.2 and GPT-5.2 in the middle of the table. Within each supplier, the most recent models systematically do better than their predecessors, with a marked acceleration for those released after the start of 2026.
Even more interesting, the researchers measured the ability of each model not to break what already works by adding new code. Claude Opus 4.6 achieves this in 76% of tasks, Claude Opus 4.5 in 51%. Afterwards, it’s a drop: Kimi-K2.5 and GLM-5 peak at 37%, GPT-5.2 falls to 23%, and the majority of models remain below 20%. In other words, for most LLMs on the market, the model breaks functional code by wanting to add new one in more than eight cases out of ten.
Keeping human feedback, a necessity
Very concretely, these results show that the gap between the best model and the rest of the pack is considerable and not only in the overall score. The gap is especially obvious in the ability to not degrade what already exists, which is basically the crux of the matter. The researchers also note that post-2026 models are progressing significantly faster than their predecessors, a sign that suppliers are starting to optimize their models for the maintainability of the code and not just for its immediate functional correctness.
The comparison remains incomplete, however, as several proprietary models have not been tested (Codex, Gemini, etc.). SWE-CI nevertheless offers a new benchmark (dataset available on Hugging Face) that each company can use to test its own models over time. These first results also confirm what the developer community already suspected: Claude Opus 4.6 clearly stands out on code maintenance tasks. However, even the best model does not guarantee flawlessness: AI can still break code in certain cases. Human supervision remains, for the time being, a much-needed safety net.